
自分の知らないところで、自分の声が、知らない曲を歌っている――そんな展開を期待してます。
2009年のクリスマス、Sinsyという歌声合成技術がデビューした。サンプリングした音の素片を結合させるVOCALOIDやUTAUとは違う、HMM(隠れマルコフモデル)という統計的な手法を用いて人間の歌声をモデリングし、本物の人間のようにリアルな歌い方が可能となっている。
Sinsyは名古屋工業大学が提供している無料のWebサービスで、電子フォーマットの楽譜をインプットすると歌声のオーディオデータを吐き出してくれる。この技術をベースにCeVIO Creative Studioという製品も今年発売された。
そして2013年のクリスマス、筆者はそのSinsyの歌声の「中の人」になった。ブラウザから誰でも使えるバーチャルシンガーになったのだ。Sinsyではこのシンガーを「ボイス」と呼ぶ。「Sinsyボイス m003e_beta 松尾P」の誕生である。
中の人になるためにすべきこと
きっかけは学会への取材だ。昨年2月に開催された情報処理学会 音楽情報科学研究会・音声言語情報処理研究会の「歌声情報処理最前線!!」で、名古屋工業大学国際音声技術研究所の徳田恵一教授と大浦圭一郎特任助教による講演「自動学習により人間のように歌う音声合成システム ―Sinsy―」があった。このとき「英語音源あると便利でいいんですよね。あと、ローカルで処理できるとうれしい」と要望を出したら、「中の人をやってみませんか?」という逆提案されたのだ。
この時点では英語を歌えるボイスはまだなかった。徳田教授は筆者が英語のカバー曲を歌っているのを知っていたのでもちかけてくれたようだ。UTAUを使って自分の英語音源を作ってみたいと考えていたけどなかなか正しいやり方にたどりつけずにいたので、これは試す価値があると思い快諾。収録の条件を聞いて、さっそく試すことにした。
VOCALOIDやUTAUとは違い、意味のない文字列を一定の音程で歌う必要はない。Sinsyの音源収録では、ただ歌を歌えばいい。今回は英語音源なので、英語の歌だ。10数曲あればいいというので、特に練習なしで歌える14曲を選んだ。
- And I Love Her
- Yesterday
- All My Loving
- Get Back
- The Fool On The Hill
- Back In The U.S.S.R.
- Here, There And Everywhere
- Blackbird
- Hey Jude
- Penny Lane
- Michelle
- Let It Be
- Lady Madonna
- The Long And Winding Road
すべてビートルズの曲で、ポール・マッカートニーがリードボーカルを取っているのを選んだ。歌いまわしとかがあまり変ってしまうとよくないだろうという、個人的な判断からだ。ポールの曲を歌うときにはできるだけ節回しを似せるように心がけているので、多少なりともポールっぽい歌声合成音源になれば、という目論見もあってのことだ。成功するしないは別にして。
これらの曲を選ぶ上でもう1つ、ポイントがあった。それはMIDIのカラオケが存在すること。この14曲については、ヤマハが販売しているMIDI演奏データを、こちらと名古屋工業大学双方で購入して使った。これを参考に、ボーカルデータと対照させる楽譜データをSinsyチームで作っていくのだ。
こちらでは、MIDIデータをQuickTime Proに読み込み、オーディオデータに変換してからiMacのGarageBandに取り込み、ボーカルを録音していった。収録場所は、なんの防音もされていない自宅リビング。2012年3月の、家族がいない時を見計らって、一気にほぼ1日で録音した。サンプリング周波数は44.1kHz。
オケは売り物なので、そのデータをそのものを出すわけにはいかないが、参考に、同じ曲を自分で作成したオケで「歌ってみた」ものがいくつかあるので、ご参考に。こんな感じである。
上記の録音でも分かるように、部屋の内外のノイズを拾ってしまっていること、本当は48kHzか96kHzでの収録が望ましいのを44.1kHzで録ったこと、さらにはMIDIデータのBPMが固定ではなかったため、ボーカルデータの後処理が大変で音質を下げてしまった。
録音から公開まで時間がかかったことにはそういった問題があったと、後で徳田教授から説明を受けた。まだこれは「Sinsyボイス m003e_beta 松尾P」とあるようにベータ版なので、音質改善のチャンスが残されている。歌ってみたが捗ると話題の「だんぼっち」でどの程度いけるのかは試してみないとわからないが、録音環境も理想的なものに少しでも近づけて再度挑戦し、品質を上げたいと考えている。
そういうわけで、このバージョンで、音質面で問題があるとすれば、それは当方の収録条件が原因。まだ良くしていきたいと思っているので、それまでは現行のベータ版でぜひ歌わせてほしい。
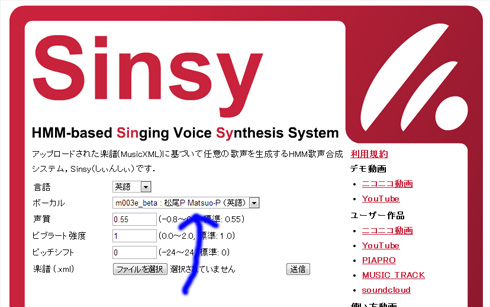
みんな俺の声を使ってください! ってことでSinsyの使い方を解説
Sinsyを使うためには、MusicXMLというフォーマットの楽譜データを作成する必要がある。筆者は五線譜で入力するFinale NotePadというフリーウェアを使っている(Mac版、Windows版がある)。Cadencii、MuseScoreといったアプリも利用可能だ。
譜面ができたらMusicXML形式で書き出し、そのファイルをSinsyにサイトで送信する。数秒待つと、.wav形式のオーディオデータで、m003e_betaが歌う英語のボーカルがダウンロードできるようになる。
楽譜をスタジオ付きシンガーの松尾P君に渡すと、スタジオの中で歌って、「できたよ」と渡してくれる――そんなイメージだ。
スタジオにいるシンガーは1人ではない。英語の歌ならば、m003e_beta(つまり、筆者の声です!)だけでなく、女声の「f002e 香鈴(シャンリン)」も使える。日本語は、同じ人が歌う「f002j 香鈴」、初号機の「f001j 謡子」。そして、UTAUでもおなじみの波音リツが「f004j 波音リツS」として加わった(デモは去年から出ていたが、使えるようになったのはこのクリスマスから)。Sinsyではこの4人、5種類の歌声を無料で使うことができる。
「調教いらず」でリアルな歌声を手に入れることができるSinsyだが、譜面で表現できないような細かいニュアンスまで「調教」することは難しい。そこはMelodyneなどのピッチエディタ(DAWに付属、内蔵するものも多い)と併用するなどの方法もある。
なお、ローカルでSinsyが使えたらいいですね、という話は今回実現した。ソースコードが公開されたからだ。Sinsyのバージョンは初期型で、0.9となる。早くも試した方のブログはこちら。
自分の知らないところで、自分が歌えない、知らない曲が自分の歌声で響いていくというのは、自分自身の理想型でもある。どんどん歌わせていってほしい。m003e_betaに歌わせたら、ニコニコ動画やYouTube、SoundCloudなどに投稿してもらえるとうれしい。
エクシングへの取材でも書いたが、HMM方式の歌声合成には、歌唱者適応という技術がある。その技術がさらに進めば、数曲しか残っていない場合でもその歌声からボイスを構築し、たくさんの人がその歌声で曲を作ってくれる。自分たちがいなくなっても続いていくものがあるとうれしい。
MMDAgentはAndroid対応に
Sinsyの兄弟分とも言える、同じく徳田チームによる製品「MMDAgent」(3Dキャラクターと対話できるソフト)もこのほどメジャーアップデートを果たした。今回はAndroid対応が目玉だ。徳田教授に聞いたところ、iOS版は人的リソースの問題から現時点で予定はないそうだ。
移植や他形態での利用については、基本的に修正BSDライセンスで公開しているため「商用利用も含めてどのように利用してもOK。ただし、COPYRIGHT表示は必須」となる。例外はメイちゃんの3Dモデルで、こちらはクリエイティブ・コモンズのCC BY-NCで公開なので「商用利用を除き、どのように利用してもOK。ただし、COPYRIGHT表示は必須」となる。
つまり、版権的に使えるMMDモデルがあれば、それを利用して独自の対話型3DエージェントをiPhone、iPad向けに作ることも可能となる。これはMMDAgent関連の開発コミュニティに期待したいところだ。

