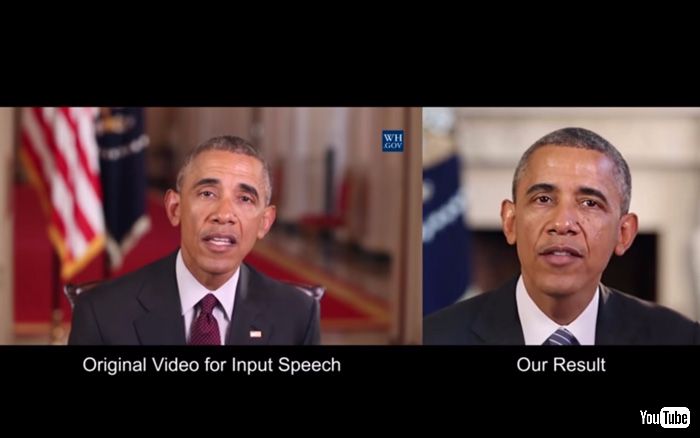
偉人がしゃべるVR映像の制作などに応用できるとのこと。
米ワシントン大学の研究者らが、機械学習を使って音声データから口の動きをリアルに再現するシステムを開発しました。
学習したデータを元に、口部分と音声だけをすり替えた合成映像を自動的に生成するというもの。インプットされた音声から、ベースとなる口の形を作った後、映像に当てはめる仕組みになっています。このシステムに関する論文を執筆したSupasorn Suwajanakorn氏によれば、口は人間が不自然さを感じやすく、「不気味の谷」に陥りやすい場所。しかし、発表された米国オバマ前大統領の合成映像はとてもリアルで、あたかも本当にしゃべっているかのように見えます。
このような合成は以前から可能だったものの、スタジオで複数人の口の動きを撮影する必要が。しかし、今回発表されたシステムはインターネット上の動画などに対応しており、低コストで使用できるようになっています。ちなみに、今回発表された合成映像にオバマ前大統領が採用されたのは、パブリックドメインの映像が何時間分も公開されているため。学習にはまだ膨大な量のデータが必要で、それをそろえるのが楽だったからというわけです。今後は、学習用映像を10分の1以下に減らし、1時間分で利用できるように改良するとしています。
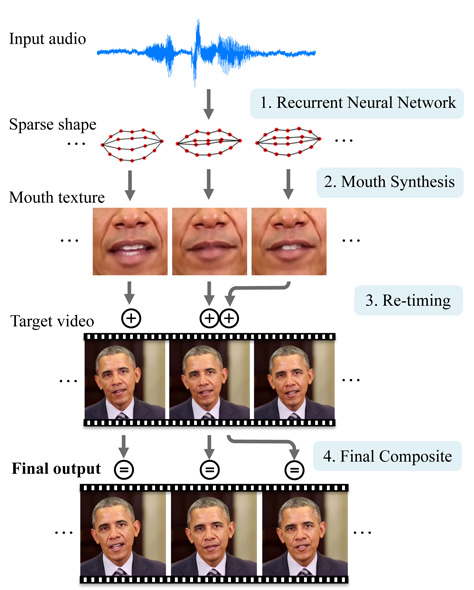
仕組みを表した図
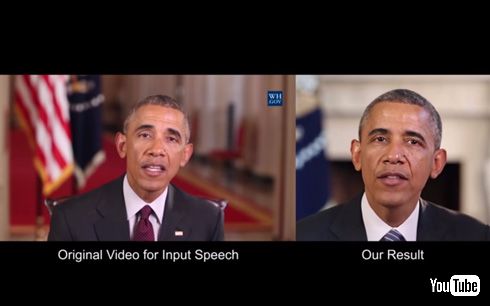
オバマ大統領が話している様子を、とてもリアルに再現しています


入力されたインタビュー映像は、構図が大きく異なるものも。音声のみを使うため、問題なく機能するようです
実用化の方向性としては、ビデオ通話への導入などが考えられるとのこと。接続状況が悪いと映像が乱れることがありますが、同システムを使えば、音声のみを使って高品質な合成映像を見せることができます。また、歴史的な人物がしゃべっている様子をリアルに再現したVR映像の制作にも活用できる可能性もあるとのこと。
(マッハ・キショ松)
