Google傘下のDeepMindが、社会科学研究に人工知能を応用した論文を発表しました。深層学習(ディープ・ラーニング)でゲームの攻略法を学ぶ人工知能「DQN」(関連記事)や、囲碁のトップ棋士を破り話題になった「AlphaGo」(関連記事)などで知られる同社。今回はAIにゲームをさせて、「囚人のジレンマ」に代表される社会的ジレンマの実験に活用しています。
社会的ジレンマとは、個人の合理的な行動が社会全体にとって合理的ではない状況のこと。例えば、「囚人のジレンマ」は共犯者2人が協力、裏切りの2択を迫られる単純なゲームのような形式で表現されていますが、今回の論文は、より現実に即したアプローチとして「sequential social dilemmas(連続的な社会的ジレンマ)」を提唱。個人間で利害関係が発生する状況をゲーム化している点は従来の方法に似ていますが、そのプレイヤーに人工知能を使って、実際にシミュレーションするのが大きく違うところです。
実験では性能差のある人工知能2種を使い、ビームで一時的に相手をフィールドから除外できるルールのもと、得点になるりんごを取り合う「Gathering」を繰り返しプレイ。りんごが十分あるうちは共存していたものの、少なくなると別のプレイヤーを攻撃するようになったといいます。また、設定が違う場合にプレイヤーの動きがどう変わるのかも調べており、りんごが豊富に出現する「パラダイスのような設定」では他のプレイヤーに攻撃しなくなります。他人と利益を奪い合うようなルールだとしても、それが気にならないくらい資源があれば、ビームを撃つ必要はないというわけです。
一方、獲物を捕まえたプレイヤー、協力したプレイヤーがともに得点できるゲーム「Wolfpack」(他人の獲物を狙うハゲタカのような生物がおり、1人きりだと奪われてしまうという状況をイメージしたルール)では、人工知能は協調的な戦略を学習。このようにルールに合わせて行動を最適化する傾向は、性能の高い人工知能のほうが強かったといいます。
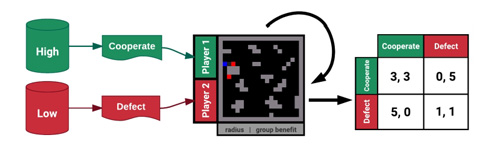
特定の状況をゲームで表現し、人工知能でその実験を行うアプローチ
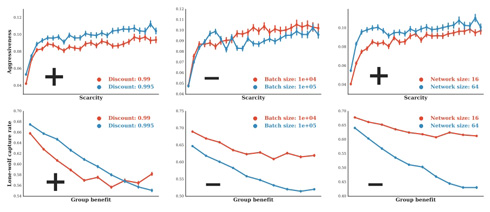
設定を変えて行動要因を調べたり、実験結果を量的なデータとして取り出せたりする点がメリットのようです
論文によれば、「sequential social dilemmas」は経済や交通、環境問題における人間の行動理解、コントロールに役立つとのこと。この手の実証実験を大規模に行おうとすると被験者を集めるのに苦労しそうですし、いくらでも動いてくれる人工知能はなかなか便利なのかもしれません。
(マッハ・キショ松)
コメントランキング
名曲だと思う「サザンオールスターズ」のシングルは?【2026年版・人気投票実施中】(投票結果) | 音楽 ねとらぼリサーチ
東京駅で絶対に買うべき“駅弁”は……「コレはすごいわ」「旨味がジュワッと広がる」【人気投票実施中!】(1/2) | 東京都 ねとらぼ
【スタジオジブリ】「ジブリヒロイン」であなたの大好きなキャラクターは誰?【2026年版・人気投票実施中】 | アニメ ねとらぼリサーチ
「平仮名にすべきだったw」 千葉県の“難読市町村名”に「冷静に考えたら不思議な読み方」「ふつうに考えてトップ難読」の声【6月15日は「千葉県民の日」】(1/2) | 千葉県 ねとらぼリサーチ
最高にうまい「とんかつチェーン」ランキングTOP23! 第1位は「とんかつ和幸」【2026年最新調査結果】(2/2) | チェーン店 ねとらぼリサーチ:2ページ目